
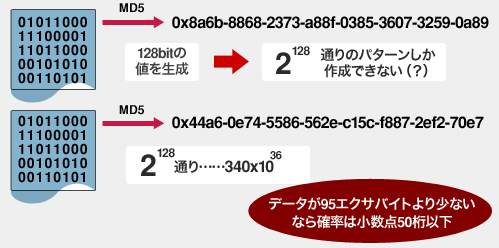
ハッシュ方式はデータをより小さいサイズのキーに置き換えて比較するため、キーのケタ数以上のブロックの管理が出来なくなります。例えば128ビットのキーを生成するMD5を利用する場合、2の128乗通り以上のブロックが存在した場合、異なるデータで同じキーをもつことになります。これがハッシュコリジョンと呼ばれます。
では、ハッシュコリジョンが発生するリスクがあるため、MD5を利用したDe-dupe製品の信頼性は低いのでしょうか?
実際、2の128通りというのどのぐらいの数でしょう。 計算すると340x10の36乗。
・10の12乗 : テラ (これはよく耳にする単位ですね。)
・10の15乗: ペタ (データセンター規模で時々聞く単位です。)
・10の18乗: エクサ(数の単位として経験したことはありません。)
・10の21乗: ゼタ
・10の24乗: ヨタ
調べた範囲でこれ以上の単位の言葉が出てきませんでした。
1ブロックを1Byteで区切ったとしても、340エクサバイトの2乗でMD5のハッシュキーは飽和します。
JDSFが愛読するSearchStorage.comのStorage Magazine の記事によれば、「格納データが95エクサバイトより少ない環境であれば、ハッシュコリジョン発生の確率は小数点50桁以下」といわれています。
実際のブロックサイズは数KB~数百KBとなっており、ハッシュ方式も128ビットのMD5から256ビットのSHA-1が主流になってきているので、ハッシュコリジョン発生によるデータのロストの確立はさらに低いものとなっています。
それでも、やっぱり100%でなければダメでしょうか。ディスクやテープや、各ソフトウェアも100%はないと思います。 |

 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
